Lassen Sie uns gemeinsam die hbird_e203 CPU lesen

Copyright-Hinweis:
Dieser Artikel ist lizenziert unter CC BY-NC-SA 4.0.
Lizenzinformationen:
- Titel: Lassen Sie uns gemeinsam die hbird_e203 CPU lesen
- Autor: EleCannonic
- Link: https://elecannonic.com/de/kategorie/electronik/e203_lesen/
Die kommerzielle Nutzung dieser Inhalte ist strengstens untersagt. Weitere Details zur Lizenzpolitik finden Sie auf der Seite Über uns.
Hinweis: Dieser Artikel ist lediglich ein Gedankengang. Bitte verwenden Sie ihn nicht als Handout, da er nicht genügend Informationen für systematisches Lernen bietet. Als Referenz ist er jedoch in Ordnung.
Als Startpunkt für einen tiefen Einblick in die Welt der CPUs ist die hbird_e203 ein gutes Projekt.
Hier ist der Projektlink: Hummingbird E203
1. Befehlssatzarchitektur (ISA)
hbird_e203 verwendet die RISC-V ISA, die einfach konzipiert ist. Befehle in der RISC-V ISA sind streng geordnet.

RISC-V unterstützt nur Little-Endian. Was ist Little-Endian und Big-Endian? Nun, lassen Sie uns eine Grafik zur Interpretation verwenden:

Wenn die ISA Little-Endian verwendet, sind die gespeicherten Daten 0x78563412. Bei Big-Endian sollte es 0x12345678 sein.
2. Standard DFF-Register
hbird_e203 verwendet modulare, Standard-DFF-Module zur Konstruktion von Registern anstelle eines always-Blocks.
1 | wire flg_r; // Ausgangssignal |
In einem anderen Modul ist sirv_gnrl_dfflr wie folgt aufgebaut:
1 | module sirv_gnrl_dfflr # ( |
Durch die Verwendung von Standardmodulen ist es bequem, den Registertyp zu ersetzen oder Verzögerungen global einzufügen. Das xchecker-Modul erfasst undefinierte Zustände. Sobald ein solcher erkannt wird, meldet es einen Fehler und bricht die Simulation ab.
3. if-else und assign
Dieses Projekt empfiehlt, if-else durch assign zu ersetzen. Denn if-else hat zwei Hauptnachteile:
if-elsekann den undefinierten ZustandXnicht übertragen.1
2
3
4if(flg)
out = in1;
else
out = in2;Wenn
flg == X, wird Verilog dies alsflg == 0behandeln, und die endgültige Ausgabe wirdout = in2sein, wasXnicht übertragen hat.Wenn jedoch
assignverwendet wird:1
assign out = flg ? in1 : in2;
Der
X-Zustand wird übertragen. Diese Übertragung erleichtert das Debugging.if-elsewird als Prioritäts-MUX synthetisiert, was zu einer großen Fläche und schlechterer Timing-Leistung führt. Nehmen wir den folgenden MUX als Beispiel:1
2
3
4
5
6
7
8if (sel1)
out = in1[3:0];
else if (sel2)
out = in2[3:0];
else if (sel3)
out = in3[3:0];
else
out = 4'b0;Nach der Synthese wird dieser Code zu:

Prioritäts-MUX
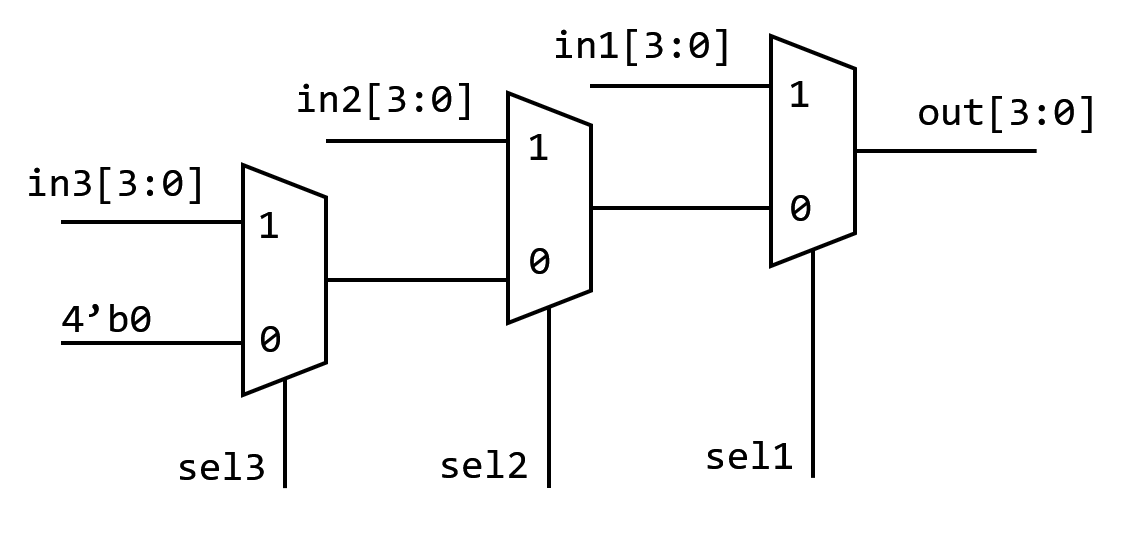
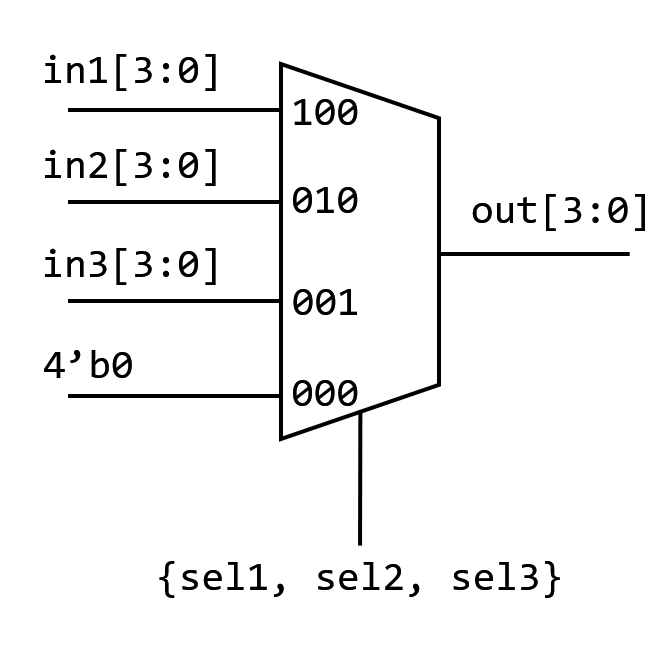
3 MUX belegen offensichtlich mehr Fläche. Aber wenn wir assign verwenden:
1 | assign out = ({4{sel1}} & in1[3:0]) |
Dies ist ein paralleler, maskierender MUX. Die sel-Signale fungieren als Maskierungssteuerungen, die parallel zu den drei in-Signalen sind. Er wird synthetisiert als:
4. Daten-Hazard
RAW (Read After Write)
Angenommen, Befehljbenötigt eine Operationsnummer, die von Befehlibereitgestellt werden soll. Daher muss das WB vonivor dem Registerlesen vonjausgeführt werden.Zum Beispiel:
1
2i: ADD x1, x2, x3 ; (x2 + x3 -> x1)
j: SUB x4, x1, x5 ; (x1 - x5 -> x4)In einer Pipeline, wenn
jgerade die ID ausführt, könnteinoch die EX ausführen, das Ergebnis wurde noch nicht in die Registerdatei geschrieben. In dieser Situation liestjeine falsche Operationsnummer.Um das Problem zu lösen, kann die Pipeline ein Stalling anwenden, um nachfolgende Befehle anzuhalten und auf das WB von
izu warten. Die gebräuchlichste Methode ist jedoch Data Forwarding. Die CPU sendet das Ergebnis von EX oder MEM vonidirekt anj, anstatt aufizu warten. Diese Methode erhöht die Effizienz im Vergleich zum Stalling.WAR (Write After Read)
Befehljversucht, in ein Register zu schreiben, aber ein anderer Befehlimuss die Operationsnummer in diesem Register lesen. Das Lesen vonimuss vor dem Schreiben vonjabgeschlossen sein.Beispiel:
1
2
3i: SUB x4, x1, x5 ; liest x1
j: ADD x1, x2, x3 ; schreibt x1
k: MUL x6, x1, x7 ; liest x1Wenn die Pipeline In-Order ist, gibt es kein Problem. In einer Out-of-Order-Pipeline kann es jedoch passieren, dass
jvorifertig wird, wennx2undx3früher bereit sind. Dann liefertiein falsches Ergebnis.Zur Lösung benennt die CPU die Register um.
1
2
3i: SUB x4, P1, x5 ; // P1 für alten x1-Wert
j: ADD P2, x2, x3 ; // P2 für neuen x1-Wert, unabhängig von P1
k: MUL x6, P2, x7 ; // Neuen Wert verwendenUm die Umbenennung zu erreichen, erstellt die CPU eine Zuordnung von der externen Registerdatei (ISA-Register) zu den internen Registern. Dann beeinflussen sich Schreiben und Lesen nicht mehr gegenseitig.
WAW (Write After Write)
Zwei Befehle,iundj, müssen beide eine Nummer in dasselbe Register schreiben. Die korrekte Reihenfolge istizuerst undjdanach. WAW tritt ebenfalls in einer Out-of-Order-Pipeline auf. Wennjzuerst fertig wird, sollte das Endergebnis das vonisein, was falsch ist.Die Lösung ist ebenfalls die Umbenennung.
5. Instruction Fetch (IF)
Das Endziel von IF ist es, “schnell” und “kontinuierlich” zu sein.
ITCM
Um IF schneller zu machen, müssen wir die Leseverzögerung des Speichers verringern. Allgemeiner Speicher kann eine Verzögerung von Dutzenden von Taktzyklen haben, was weit davon entfernt ist, unsere Anforderungen zu erfüllen.
Im Allgemeinen erstellt eine moderne CPU einen kleinen Speicher (Dutzende von KB) zur Speicherung von Befehlen, der physisch nahe am Kern liegt. Dieser Speicher wird als ITCM (Instruction Tightly Coupled Memory) bezeichnet.
ITCM ist kein DDR oder Cache. Es ist nur ein kleiner Speicher mit einer bestimmten Adresse. Die Verzögerung ist im Vergleich zum Cache vorhersagbar. Daher bevorzugen Ingenieure in Situationen mit hohen Leistungsanforderungen die Verwendung von ITCM.
Nicht-ausgerichtete Befehle
RISC-V unterstützt komprimierte Befehle (C-Erweiterung). Die CPU muss mit einer Mischung aus 32-Bit- und 16-Bit-Befehlen umgehen. Wie weiß die CPU also, ob es sich um einen 32-Bit- oder einen 16-Bit-Befehl handelt?
Die beiden niedrigstwertigen Bits des Opcode für einen 32-Bit RISC-V-Befehl müssen 0b11 sein.
Die CPU unterscheidet die Befehle anhand der beiden niedrigstwertigen Bits (nennen wir sie unten LS2B). Wenn die LS2B 0b11 ist, ist es 32 Bit; wenn nicht, ist es 16 Bit.
Wie geht die CPU damit um? Lassen Sie uns den Ablauf im Detail klären.
Komponenten
- Fetch Width: Aus Effizienzgründen holt die CPU mehr als ein Halbwort auf einmal aus dem ITCM. Sie holt normalerweise mehr, zum Beispiel 32 Bit.
- Instruction Prefetch Queue (IPQ): Ein FIFO zwischen IFU und Decoder.
- RISC-V-Regel: Wenn
LS2B = 0b11, ist es ein 32-Bit-Befehl; andernfalls ist es ein 16-Bit-Befehl.
Arbeitsablauf
Gemäß dem PC-Wert holt die IFU ein Wort (32 Bit) aus dem ITCM und fügt es unten in die IPQ ein.
Die ID holt ein Halbwort (16 Bit) vom oberen Ende der IPQ und prüft dann, ob es sich um einen komprimierten Befehl handelt.
- Situation A: Es ist ein 16-Bit-komprimierter Befehl
Die ID verbraucht die ersten 16 Bit in der IPQ und sendet sie als vollständigen Befehl an die nachfolgenden Abschnitte. Der Zeiger der IPQ bewegt sich um 2 Bytes. - Situation B: Es ist Teil eines 32-Bit-Befehls
Die ID benötigt mehr Daten. Sie verbraucht die ersten 32 Bit in der IPQ und sendet sie dann an den nachfolgenden Abschnitt. Der Zeiger der IPQ bewegt sich um 4 Bytes.
- Situation A: Es ist ein 16-Bit-komprimierter Befehl
Diese Schritte werden wiederholt. Wenn die Daten in der IPQ weniger als 32 Bit betragen, führt die IFU den nächsten 32-Bit-Lesevorgang durch und füllt die Daten am Ende der IPQ auf.
Sprungbefehle
Es gibt zwei Arten von Sprungbefehlen in RISC-V.
Unbedingter Sprung: Urteilsbedingungen sind nicht erforderlich. Es gibt auch zwei Arten von unbedingten Sprüngen.
Direkt: Die Zieladresse kann direkt durch
immim Befehl berechnet werden.Beispiel:
jal x5, imm,immist 20 Bit, Sprung zur Adresse2*imm + PC.Indirekt: Die Zieladresse muss aus Daten in der Registerdatei berechnet werden.
Beispiel:
jalr x1, x6, imm,immist 12 Bit, Sprung zur Adresseimm + x6.
Bedingter Sprung: Sprung mit Bedingungen
Immer noch zwei Arten: Direkt und Indirekt. Aber es gibt keine indirekten Befehle in RISC-V.
Sprungvorhersage
Löst zwei Probleme:
- Ob gesprungen werden soll (Richtung)
- Was die Zieladresse ist (Adresse)
Statische Vorhersage: Immer die gleiche Ausfallwahrscheinlichkeit vorhersagen oder einem festen Muster folgen. (BTFN)
Sprungrichtung: Ziel-PC < Aktueller PC, genannt zurück; andernfalls vorwärts genannt.
Dynamisch:
1-Bit-Sättigung: Verwendet die letzte Richtung zur Vorhersage. Wird bei Fehlern geändert.
2-Bit-Sättigung:
Betrachten Sie die Zustandsmaschine:
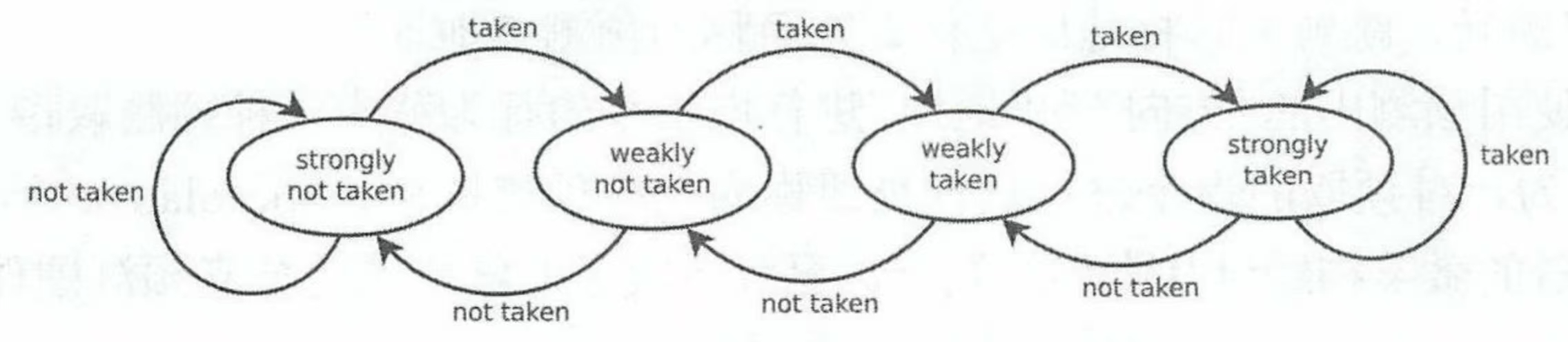
2-Bit-Sättigung ist effektiv bei der Vorhersage eines einzelnen Befehls. Aber für viele Befehle (an verschiedenen PC-Adressen) nicht. (Sie werden sich überschneiden) Idealerweise sollte jeder Sprungbefehl seinen eigenen Prädiktor haben, was zu inakzeptablen Hardwarekosten führen würde. Daher gibt es in der Praxis nur eine endliche Anzahl von Prädiktoren, die eine Tabelle bilden (Branch Prediction Table).
Genaues Vorhersageverfahren: Indizierung
- Ein Befehl tritt in die Pipeline ein, mit
PC = 0x12345678. - Die CPU nimmt die unteren sieben Bits (z. B. 10), Index
0x678 = 0d1656. - Die CPU greift mit dem Index
0d1656auf die BPT zu und findet einen 2-Bit-Sättigungsprädiktor. - Vorhersage läuft durch den Prädiktor, Zustände werden aktualisiert, …
Tatsächlich ist die Anzahl der Befehle weitaus größer als die der Prädiktoren. Daher müssen viele verschiedene Befehle denselben Prädiktor verwenden. Dieses Problem wird als Aliasing bezeichnet.
Es gibt eine kompliziertere Methode mit besserer Leistung, die Correlation-Based Branch Predictor genannt wird.
- Warum wir sie brauchen
Betrachten Sie einen Code
1 | if (a > 10) { // Sprung A |
Ob B springt, hängt sowohl von b > 20 als auch vom Ergebnis von Sprung A ab. Wenn A nicht gesprungen ist, darf B nicht springen. Eine einzelne Prädiktortabelle kann diese Situation nicht bewältigen.
Zwei Komponenten:
- Global History Register (GHR): Breite
N, zeichnet Ergebnisse der letztenNBefehle auf. - Pattern History Table (PHT): Ein Array, das aus 2-Bit-Zählern besteht.
Indexmethode: PC ^ GHR.
Die 2-Bit-Zähler zeichnen auf, “wenn die globale Historie ein bestimmtes Muster aufweist, wie sich Sprung B verhält”, anstatt die Historie von Sprung B selbst.
Verfahren:
Angenommen, GHR hat eine Breite von 2 Bit. Anfangszustand 00.
Ausführung 1: Angenommen,
a = 5, A springt nicht, aufgezeichnet als0, GHR wird nach links verschoben,0wird in das LSB von GHR gefüllt.
GHR =00.
B springt nicht, aufgezeichnet als0, GHR wird nach links verschoben,0wird in das LSB von GHR gefüllt.Ausführung 2: Angenommen,
a = 15, b = 25, A springt, GHR =01.
Vor der Ausführung von B wird der Index erzeugt,idx = Hash(PC_B, 01).
Finden Sie einen 2-Bit-Zähler (angenommen, der Anfangszustand ist11, was bedeutet, dass B dazu neigt, nicht zu springen, wenn der letzte Sprung stattfand).Vorhersage machen: B wird nicht springen.
Tatsächliches Ergebnis: Vorhersage fehlgeschlagen!
Zähler:11 -> 10.
GHR:01 -> 11.
Diese Schritte wiederholen sich.
6. E200 IFU-Implementierung
RISC-V platziert die Längenanzeige in den niedrigstwertigen Bits. Daher kann die IF-Logik die Länge erkennen, sobald sie die niedrigstwertigen Bits abruft. Darüber hinaus, da der komprimierte Befehlssatz optional ist, kann die CPU, wenn sie nicht für die Unterstützung des komprimierten Satzes ausgelegt ist, die niedrigstwertigen Bits direkt ignorieren, was etwa 6,25 % der I-Cache-Kosten spart.
Gesamtkonzept des Designs
Das IFU-Modul hat folgende Mikroarchitektur:
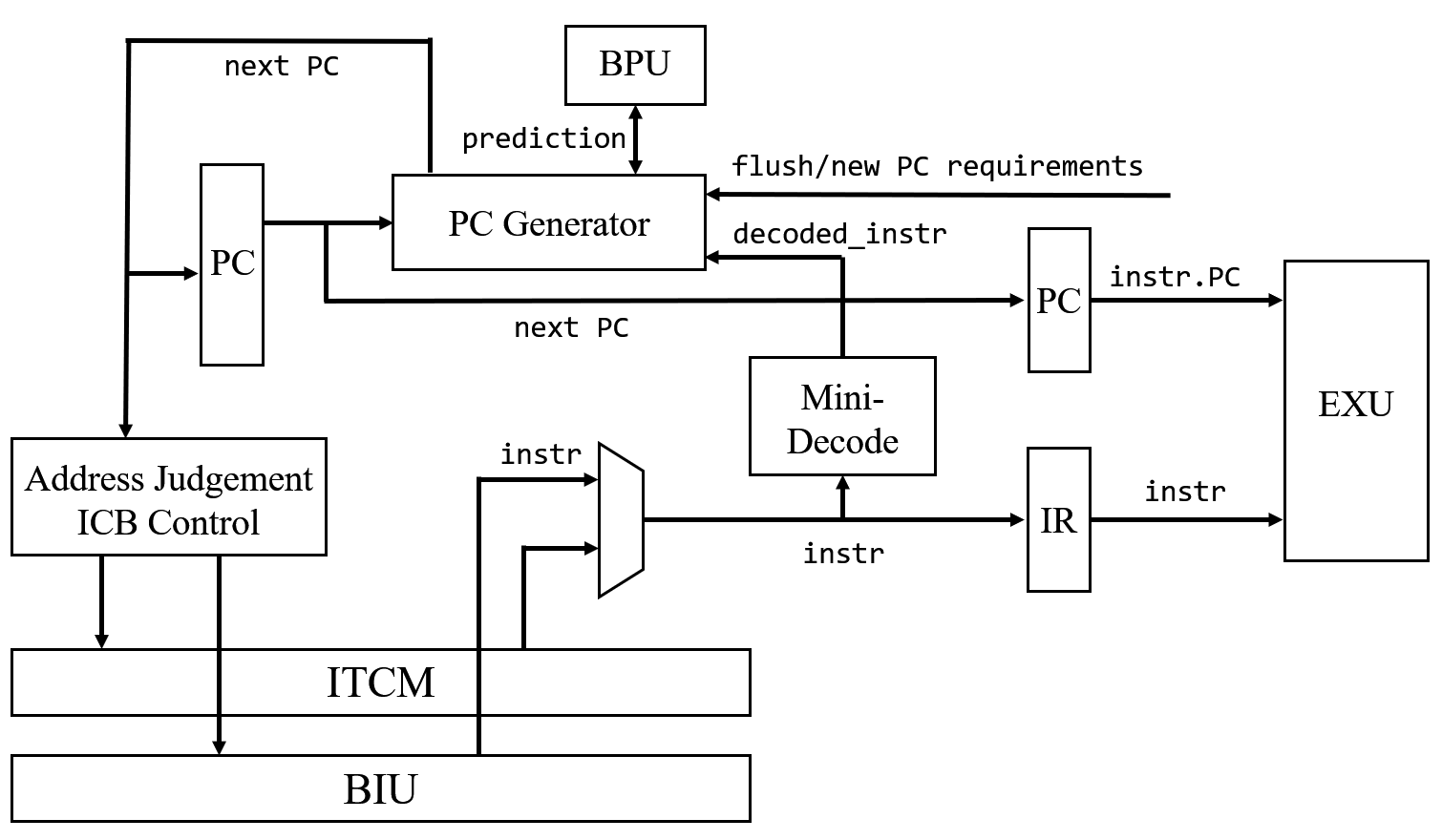
Es versucht, Befehle “schnell” und “kontinuierlich” abzurufen. E203 geht davon aus, dass die meisten Befehle im ITCM gespeichert sind, da es für extrem stromsparende, eingebettete Fälle konzipiert ist und niemals lange Codes lädt. Normalerweise können alle Codes im ITCM geladen werden.
Das IF-Modul kann einen Befehl in nur einem Zyklus abrufen, was die Anforderung an Schnelligkeit erfüllt. Wenn es Befehle von der BIU abrufen muss, gibt es mehr Verzögerung, aber solche Fälle sind viel seltener als ITCM. Daher hat E203 keine Optimierungen für diese Fälle vorgenommen (für höhere Leistung wäre eine solche Optimierung jedoch möglicherweise notwendig).
Für “kontinuierlich” muss die IF jedes Mal den nächsten PC-Wert vorhersagen. Die IF dekodiert teilweise den abgerufenen Befehl und prüft, ob er springen muss. Wenn ja, läuft der Branch Predictor im selben Zyklus, und die IF verwendet das Ergebnis und die dekodierten Informationen, um den nächsten PC zu generieren.
Mini-Dekodierung
Dieses Modul muss nur prüfen, ob es sich um einen allgemeinen Befehl oder einen Sprungbefehl handelt. Um den Designprozess zu vereinfachen, wird dieses Modul durch Instanziierung eines vollständigen Dekodierungsmoduls mit nicht verbundenen Eingängen, die auf Masse gelegt sind, und nicht verbundenen Ausgängen implementiert. Synthesewerkzeuge optimieren die redundanten Logiken und erreichen schließlich eine Mini-Dekodierung.
1 |
|
Wir werden das Dekodierungsmodul in den folgenden Abschnitten im Detail untersuchen, nicht hier.
Ready/Valid Handshake
Der Ready/Valid-Handshake ist ein Protokoll zur Gewährleistung korrekter Datenübergänge zwischen zwei Geräten.
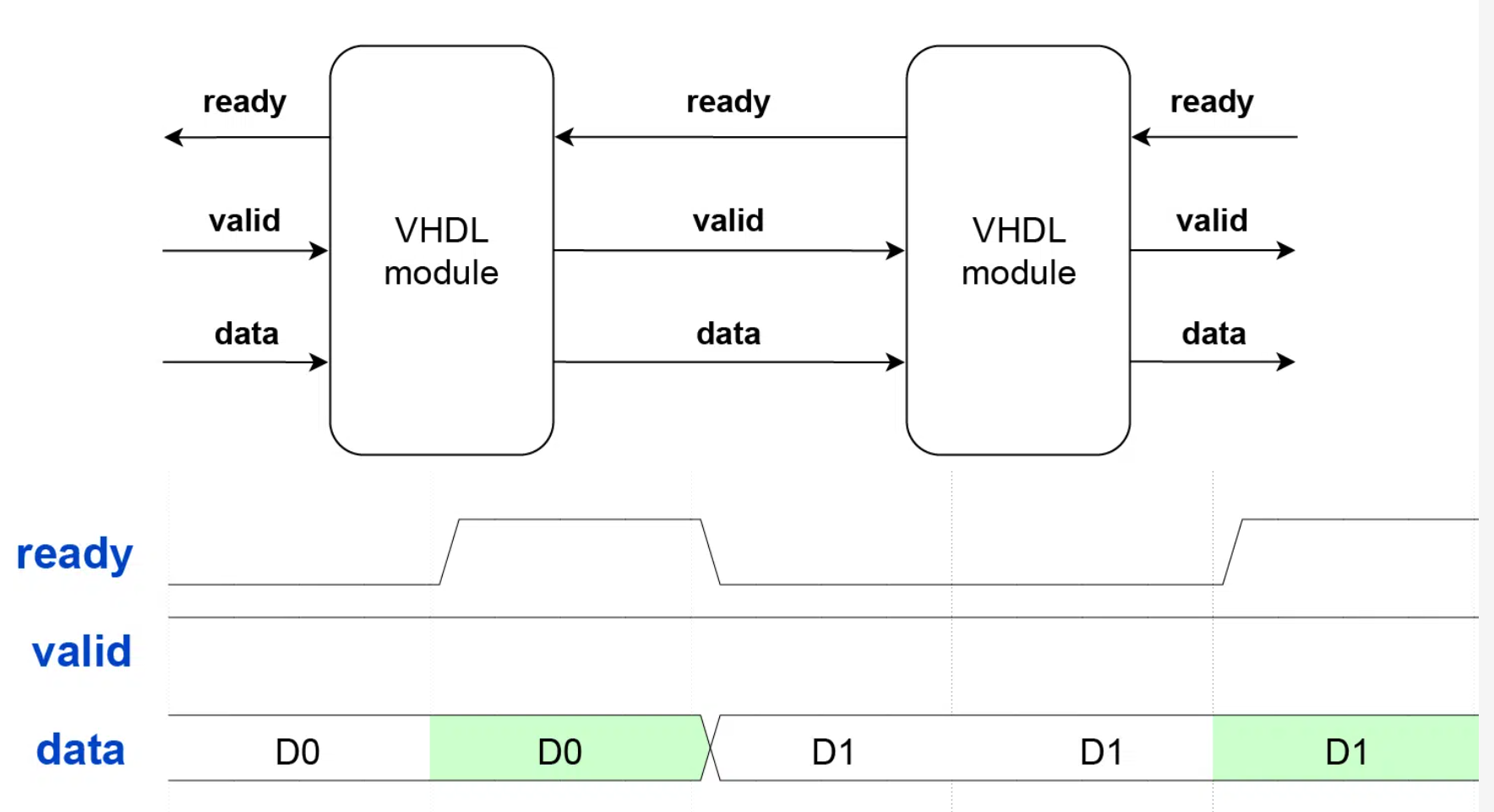
Die Regeln sind unkompliziert: Die Datenübertragung findet nur statt, wenn sowohl ready als auch valid im selben Taktzyklus auf ‘1‘ stehen. Der Handshake ist ein zustandsloses Protokoll. Keine der Parteien muss sich an frühere Taktzyklen erinnern, um zu bestimmen, ob in einem bestimmten Zyklus eine Datenübertragung stattfindet. Darüber hinaus müssen beide Parteien synchron arbeiten und die Steuersignale an derselben Taktflanke lesen. Aus diesem Grund ist Ready/Valid nicht für Clock Domain Crossing (CDC) geeignet.
Einfacher BPU-Sprungprädiktor
Um niedrigen Stromverbrauch zu erreichen, verwendet E203 die einfachste stationäre Vorhersage. Für bedingte direkte Sprungbefehle wird ein Rückwärtssprung als erforderlich vorhergesagt; andernfalls wird vorhergesagt, dass kein Sprung erforderlich ist. Gleichzeitig generiert die BPU die nächste PC über einen PC + offset-Addierer.
Die Datei befindet sich im Modul e203_ifu_litebpu.v
1 |
|
In der RISC-V-Struktur wird x1 standardmäßig als “Rücksprungadresse” verwendet. In den meisten Fällen geben jal und jalr die Adresse des nächsten Befehls an x1 zurück, wenn sie nicht speziell zugewiesen sind. Daher wird in den meisten Fällen die Adresse in x1 gespeichert. Zur Leistungssteigerung hat E203 eine spezielle Beschleunigung für x1 implementiert.
1 | wire dec_jalr_rs1x1 = (dec_jalr_rs1idx == `E203_RFIDX_WIDTH'd1); |
Diese Zeile wird verwendet, um zu beurteilen, ob jalr x1 verwendet hat. Darüber hinaus muss beurteilt werden, ob eine RAW-Abhängigkeit besteht. Eine RAW-Abhängigkeit besteht, wenn
- OITF nicht leer ist, was bedeutet, dass ein langer Befehl ausgeführt wird. Das Ergebnis könnte nach
x1zurückgeschrieben werden.
(Natürlich kann es auch andere Register verwenden, aber hier wird eine konservative Schätzung angewendet, um die Fläche zu reduzieren. Der Leistungsverlust wird ignoriert.) - Der Befehl im IR-Register schreibt das Ergebnis zurück nach
x1.
Daher
1 | wire jalr_rs1x1_dep = dec_i_valid & dec_jalr & dec_jalr_rs1x1 & ((~oitf_empty) | (jalr_rs1idx_cam_irrdidx)); |
wird verwendet, um eine Abhängigkeit anzuzeigen. Die folgende Zeile
1 | assign bpu_wait = jalr_rs1x1_dep | jalr_rs1xn_dep | rs1xn_rdrf_set; |
aktiviert bpu_wait für einen Zyklus, wenn eine Abhängigkeit erkannt wird. Ein solches Signal stoppt die nächste PC-Generierung der IFU, bis der RAW verschwindet. Im Allgemeinen verursacht eine solche Verzögerung (Stall) einen Leistungsverlust von einem Stall-Zyklus.
Wenn jalr andere Register als x0 und x1 verwendet, hat E203 keine spezielle Beschleunigung angewendet. Um xn zu lesen, wird der erste Port der Registerdatei benötigt. Nur wenn der Port frei ist, kann xn gelesen werden. Gleichzeitig muss IR leer sein, um RAW zu verhindern (ähnlich wird der Leistungsverlust ignoriert). Wenn sowohl RAW als auch Leseport frei sind, wird der Port-Enable aktiviert und belegt.
1 | wire rs1xn_rdrf_set = (~rs1xn_rdrf_r) & dec_i_valid & dec_jalr & dec_jalr_rs1xn & ((~jalr_rs1xn_dep) | jalr_rs1xn_dep_ir_clr); |
Speicherzugriff
Zur Verbesserung der Code-Dichte unterstützt E203 16-Bit-komprimierte RISC-V-Befehlssätze. Daher werden 32-Bit-Befehle mit 16-Bit-Befehlen gemischt, was zu nicht ausgerichteten 32-Bit-Befehlen führt.
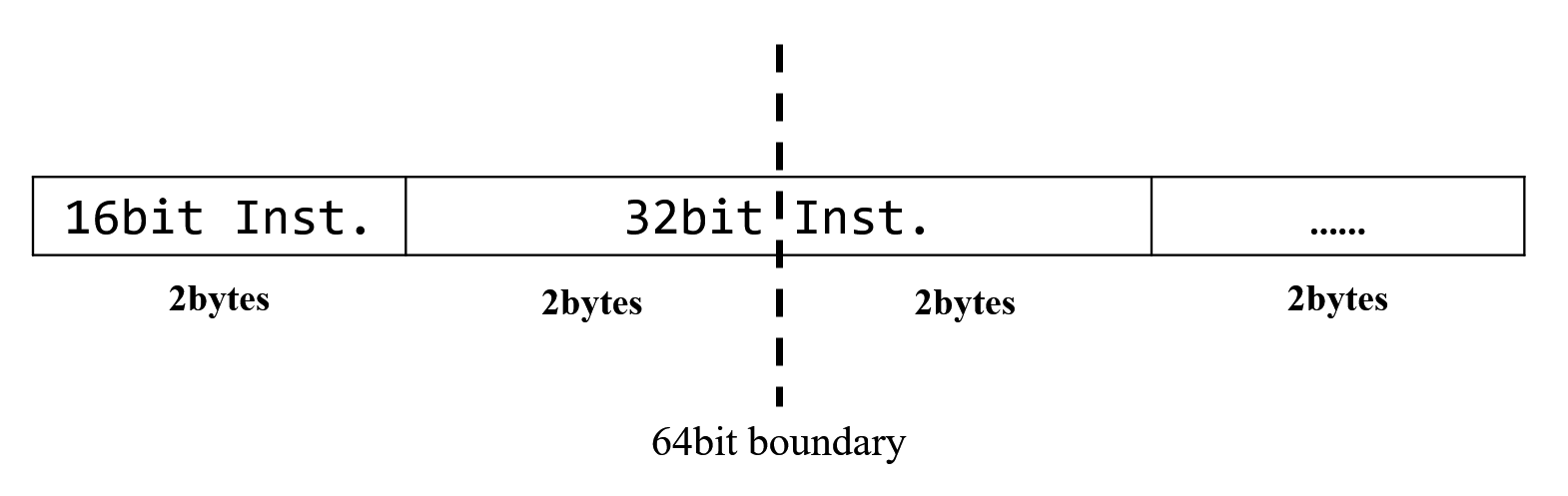
Um damit umzugehen, verwendet E203 einen Restpuffer. Die IFU holt jedes Mal 32 Bit aus dem ITCM oder BIU. Wenn die IFU auf das ITCM zugreift, da das ITCM aus SRAM besteht, bleibt der Wert am Port nach dem Lesen gehalten (unverändert), bis zum nächsten Lesen. Eine solche Eigenschaft spart ein 64-Bit-Register.
Die Bitbreite des ITCM in E203 beträgt 64 Bit. Ein Lesezugriff liest 64 Bit Daten vom Port, genannt eine Lane. Beim Abrufen durch Erhöhen der Adresse holt die IFU Daten aus derselben Lane mehrmals, da RISC-V-Befehle in E203 höchstens 32 Bit lang sind. Dies reduziert die Anzahl der SRAM-Lesevorgänge, da die IFU Daten aus dem gehaltenen Portwert lesen kann, bis alle Daten gelesen sind.
Wenn ein 32-Bit-Befehl eine 64-Bit-Grenze überschreitet, werden die verbleibenden 16-Bit-Daten im Restpuffer gespeichert und lösen einen neuen SRAM-Zugriff aus. Die niedrigsten 16 Bit der neuen 64-Bit-Daten aus SRAM und die 16 Bit im Restpuffer werden zu einem vollständigen 32-Bit-Befehl verkettet. Dies entspricht dem Abrufen eines 32-Bit-Befehls in einem Zyklus, ohne Leistungsverlust.
Wenn ein Sprungbefehl oder eine Pipeline-Flush auftritt und der gewünschte Befehl eine 64-Bit-Grenze überschreitet, sind zwei kontinuierliche SRAM-Lesevorgänge erforderlich. Das bedeutet, dass das Abrufen zwei Zyklen kosten muss, was einen Zyklusverlust verursacht. E203 verzichtet auf die Optimierung, da sie zu viel zusätzlichen Flächen- und Kostenaufwand mit sich bringen würde.
Referenzen:
[1] 胡振波, RISC-V架构与嵌入式开发快速入门, 1. Auflage. Peking:人民邮电出版社, 2019.
[2] 胡振波, 手把手教你设计CPU——RISC-V处理器, 1. Auflage. Peking:人民邮电出版社, 2018.