一起阅读 hbird_e203 CPU源代码

版权声明:
本文采用 CC BY-NC-SA 4.0 许可协议。
许可信息:
- 标题:一起阅读 hbird_e203 CPU源代码
- 作者:EleCannonic
- 链接:https://elecannonic.com/zh/categories/电子工程/e203/
严禁将本文内容用于商业用途。有关许可政策的更多详情,请访问 关于 页面。
注意:本文仅为思路记录,信息量不足以进行系统学习,请勿作为教材使用。可作为参考。
作为深入了解 CPU 世界的开端,
hbird_e203 是一个不错的项目。
项目链接如下:Hummingbird E203
1. 指令集架构 (ISA)
hbird_e203 应用了 RISC-V ISA,
其设计简洁。
RISC-V ISA 中的指令是严格排序的。

RISC-V 只支持小端序。
什么是小端序和大端序?
嗯,让我们用一张图来解释:

如果 ISA 应用小端序,
存储的数据是 0x78563412。
如果是大端序,
则应为 0x12345678。
2. 标准 DFF 寄存器
hbird_e203 使用模块化的标准 DFF 模块来构建寄存器,
而不是使用 always 块。
1 | wire flg_r; // output signal |
在另一个模块中,sirv_gnrl_dfflr 设计如下:
1 | module sirv_gnrl_dfflr # ( |
使用标准模块,
可以方便地全局替换寄存器类型或插入延迟。xchecker 模块捕获未定义状态。
一旦检测到,它会报告错误并中止仿真。
3. if-else 和 assign
本项目建议用 assign 替换 if-else。
因为 if-else 有两个主要缺点:
if-else无法传递未定义状态X。1
2
3
4if(flg)
out = in1;
else
out = in2;如果
flg == X,verilog 会将其等同于flg == 0,
最终输出将是out = in2,
这并没有传递X状态。然而,如果使用
assign1
assign out = flg ? in1 : in2;
X状态将被传递。
这种传递将使调试更容易。if-else会被综合成优先级多路选择器 (MUX),
这会带来较大的面积和较差的时序。
以下面的 MUX 为例:1
2
3
4
5
6
7
8if (sel1)
out = in1[3:0];
else if (sel2)
out = in2[3:0];
else if (sel3)
out = in3[3:0];
else
out = 4'b0;综合后,这段代码会变成

优先级 MUX
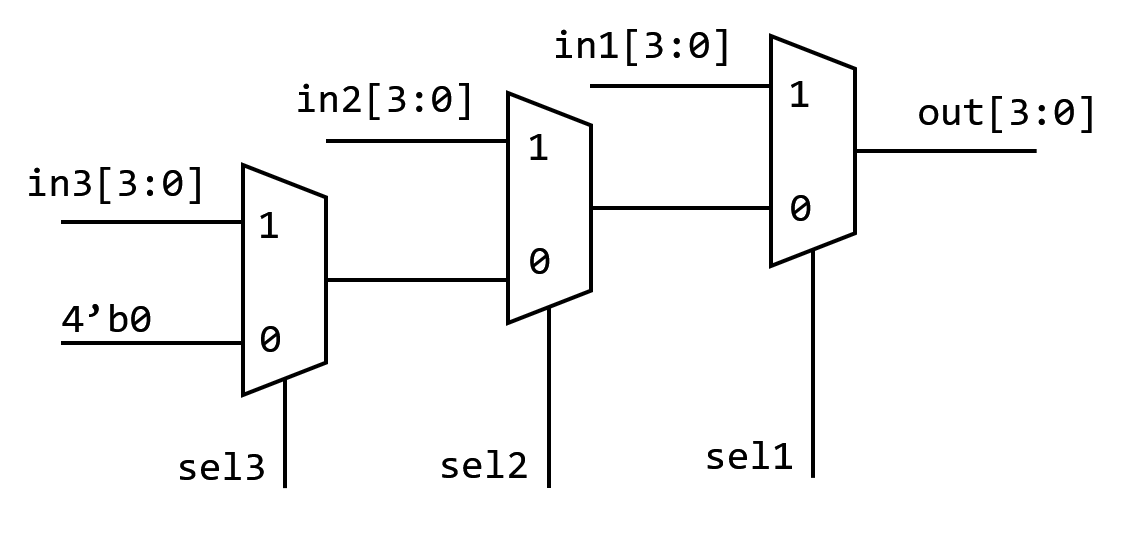
3 个 MUX 显然会占用更大的面积。
但如果我们使用 assign:
1 | assign out = ({4{sel1}} & in1[3:0]) |
这是一个并行门控 MUX。sel 信号充当门控控制,
它们并行地作用于三个 in 信号。
它将被综合成
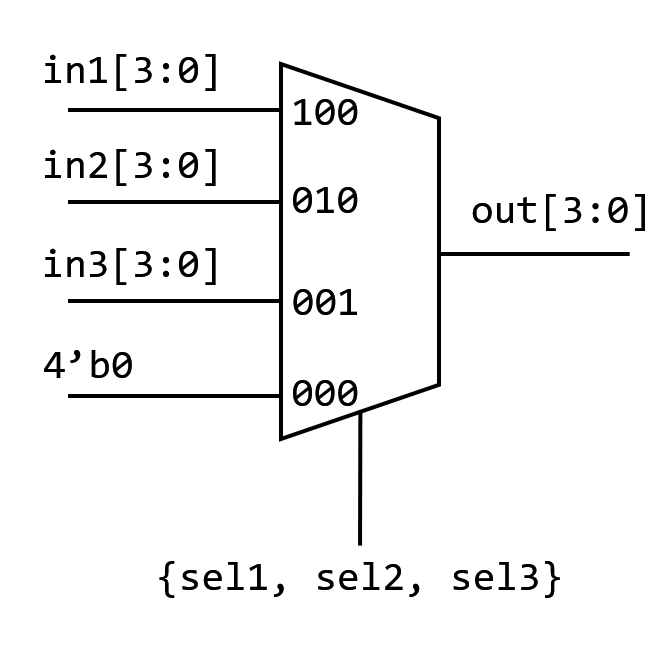
4. 数据冒险
RAW (Read After Write) - 写后读
假设指令j需要一个操作数,
该操作数应由指令i提供。
因此,i的写回 (WB) 必须在j的寄存器读取之前执行。例如:
1
2i: ADD x1, x2, x3 ; (x2 + x3 -> x1)
j: SUB x4, x1, x5 ; (x1 - x5 -> x4)在流水线中,
当j执行 ID (指令译码) 时,i可能仍在执行 EX (执行),
结果尚未写入寄存器堆。
在这种情况下,j将读取错误的操作数。为了解决这个问题,
流水线可以应用停顿 (stalling) 来暂停后续指令,
等待i的写回。
但最常用的方法是数据转发 (Data Forwarding)。
CPU 将直接将i的 EX 或 MEM (访存) 阶段的结果发送给j,
而不是等待i完成写回。
与停顿相比,这种方法提高了效率。WAR (Write After Read) - 读后写
指令j尝试写入一个寄存器,
但另一条指令i需要读取该寄存器中的操作数。i的读取必须在j的写入之前完成。示例:
1
2
3i: SUB x4, x1, x5 ; read x1
j: ADD x1, x2, x3 ; write x1
k: MUL x6, x1, x7 ; read x1如果流水线是按序执行的 (in-order),
则没有问题。
然而,在乱序执行 (out-of-order) 的流水线中,
如果x2和x3提前准备好,j可能比i先完成执行。
那么i将得到错误的结果。为了解决这个问题,CPU 会重命名寄存器。
1
2
3i: SUB x4, P1, x5 ; // P1 代表旧的 x1 值
j: ADD P2, x2, x3 ; // P2 代表新的 x1 值,与 P1 无关
k: MUL x6, P2, x7 ; // 使用新值为了实现重命名,
CPU 会创建一个从外部寄存器文件 (ISA 寄存器) 到内部寄存器的映射表。
然后写入和读取就不会相互影响了。WAW (Write After Write) - 写后写
两条指令i和j,
都将一个数字写入同一个寄存器。
正确的顺序是i先写,j后写。
同样,WAW 也发生在乱序执行的流水线中。
如果j先完成,
最终结果应该是i的结果,这是错误的。解决方案也是重命名。
5. 指令获取 (IF)
IF 的最终目标是“快速”和“连续”。
ITCM
为了使 IF 更快,
我们需要减小内存的读取延迟。
通用内存可能有几十个时钟周期的延迟,
这远远不能满足我们的要求。
通常,现代 CPU 会创建一个小型内存(几十 KB)
用于存储指令,
它物理上靠近核心。
这个内存称为 ITCM (指令紧耦合内存)。
ITCM 不是 DDR 或缓存。
它只是一个具有特定地址的小型内存。
与缓存相比,其延迟是可预测的。
因此,在高性能要求的场合,
工程师倾向于使用 ITCM。
非对齐指令
RISC-V 支持压缩指令 (C 扩展)。
CPU 需要处理 32 位和 16 位指令的混合。
那么 CPU 如何知道它是 32 位还是 16 位指令呢?
32 位 RISC-V 指令的操作码的最低两位必须是 0b11。
CPU 根据最低两位(称之为 LS2B)来区分指令。
如果 LS2B 是 0b11,则是 32 位;
否则是 16 位。
那么 CPU 如何处理它们呢?
让我们详细说明流程。
组件
- 获取宽度 (Fetch Width):为了效率,CPU 会一次性从 ITCM 获取超过半个字的数据。
它通常获取更多,例如 32 位。 - 指令预取队列 (Instruction Prefetch Queue, IPQ):
IFU 和解码器之间的 FIFO。 - RISC-V 规则:
如果LS2B = 0b11,则是 32 位指令;否则是 16 位指令。
- 获取宽度 (Fetch Width):为了效率,CPU 会一次性从 ITCM 获取超过半个字的数据。
工作流程
根据 PC 值,IFU 从 ITCM 获取一个字 (32 位) 并将其插入 IPQ 的底部。
ID 从 IPQ 的顶部获取一个半字 (16 位),然后判断它是否是压缩指令。
情况 A:是 16 位压缩指令
ID 消耗 IPQ 中的前 16 位,并将它们作为一个完整的指令发送给后续部分。
IPQ 的指针移动 2 字节。情况 B:是 32 位指令的一部分
ID 需要更多数据。它消耗 IPQ 中的前 32 位,然后将其发送给后续部分。
IPQ 的指针移动 4 字节。
这些步骤将重复进行。
当 IPQ 中的数据少于 32 位时,
IFU 将执行下一次 32 位读取操作,并将数据填充到 IPQ 的末尾。
分支指令
RISC-V 中有两种分支指令。
无条件跳转:无需判断条件。
也有两种无条件跳转。直接跳转:目标地址可以通过指令中的
imm直接计算。示例:
jal x5, imm,imm是 20 位,跳转到地址2*imm + PC。间接跳转:目标地址需要从寄存器堆中的数据计算。
示例:
jalr x1, x6, imm,imm是 12 位,跳转到地址imm + x6。
条件跳转:带条件的跳转。
同样有两种类型:直接和间接。但在 RISC-V 中没有间接指令。
分支预测
解决两个问题:
- 是否跳转 (方向)
- 目标地址是什么 (地址)
静态预测:始终预测相同的结局或遵循固定模式。(BTFN - Branch To False Not taken)
跳转方向:目标 PC < 当前 PC,称为回跳 (back);否则称为前跳 (forward)。
动态预测:
1 位饱和计数器:使用上一次的方向进行预测。
出错时进行修改。2 位饱和计数器:
查看状态机:
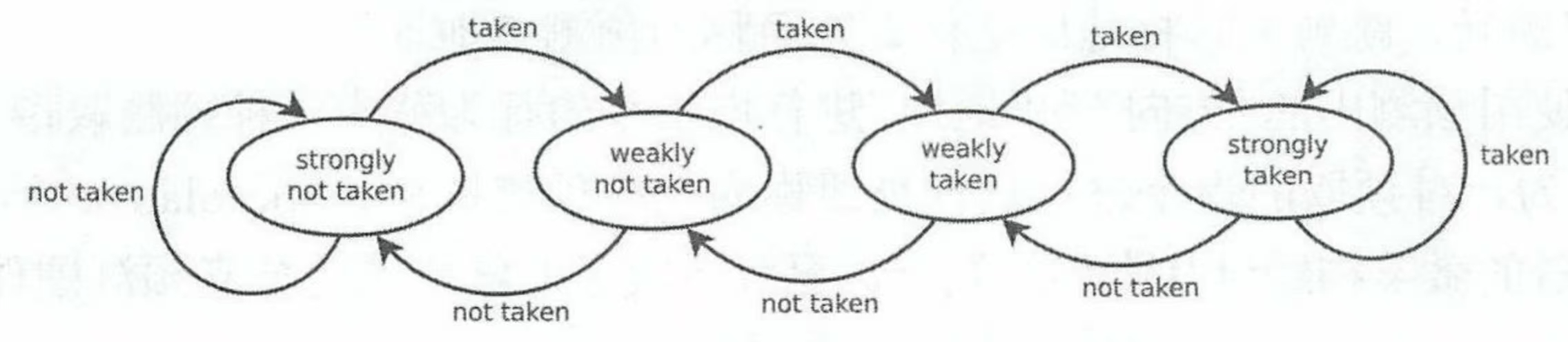
2 位饱和计数器对于预测单个指令是有效的。
但对于许多指令(在不同 PC 地址)则不然。
(它们会发生冲突)
理想情况下,每条跳转指令都应该有自己的预测器,
但这会带来不可接受的硬件成本。
因此,在实践中,只有有限的预测器组成一个表(分支预测表)。
准确预测过程:索引
- 一条指令进入流水线,
PC = 0x12345678。 - CPU 取最低几位(例如 10 位),索引
0x678 = 0d1656。 - CPU 使用索引
0d1656访问 BPT (Branch Prediction Table),找到一个 2 位饱和计数器。 - 预测器运行预测,更新状态,…
事实上,指令的数量远大于预测器的数量。
因此,许多不同的指令必须使用相同的预测器。
这个问题称为**别名 (Aliasing)**。
有一种更复杂但性能更好的方法,
称为**基于相关性的分支预测器 (Correlation-Based Branch Predictor)**。
- 为什么需要它
考虑一段代码
1 | if (a > 10) { // branch A |
B 是否跳转取决于 b > 20 和分支 A 的结果。
如果 A 没有跳转,B 也必须不跳转。
单个预测器表无法处理这种情况。
两个组件:
- 全局历史寄存器 (Global History Register, GHR):宽度为
N,记录最近N条指令的结果。 - 模式历史表 (Pattern History Table, PHT):由 2 位计数器组成的数组。
索引方法:PC ^ GHR。
2 位计数器记录“当全局历史处于某种模式时,分支 B 将如何执行”,
而不是分支 B 本身的历史。
过程:
假设 GHR 宽度为 2 位。初始状态为 00。
执行 1:假设
a = 5,A 不跳转,记录为0,GHR 左移,在 LSB 填充0。
GHR =00。
B 不跳转,记录为0,GHR 左移,在 LSB 填充0。执行 2:假设
a = 15, b = 25,A 跳转,GHR =01。
执行 B 之前,生成索引,idx = Hash(PC_B, 01)。
找到一个 2 位计数器(假设初始状态为11,
表示上次分支跳转时,B 倾向于不跳转)。进行预测:B 将不跳转。
实际结果:预测失败!
计数器:11 -> 10。
GHR:01 -> 11。
这些步骤重复进行。
6. E200 IFU 实现
RISC-V 将长度指示器放在最低有效位。
因此,IF 逻辑可以在获取最低位后立即识别长度。
更重要的是,
由于压缩指令集是可选的,
如果 CPU 未设计为支持压缩集,
它可以直接忽略最低位,
这可以节省约 6.25% 的 I-cache 成本。
整体设计理念
IFU 模块具有如下微架构:
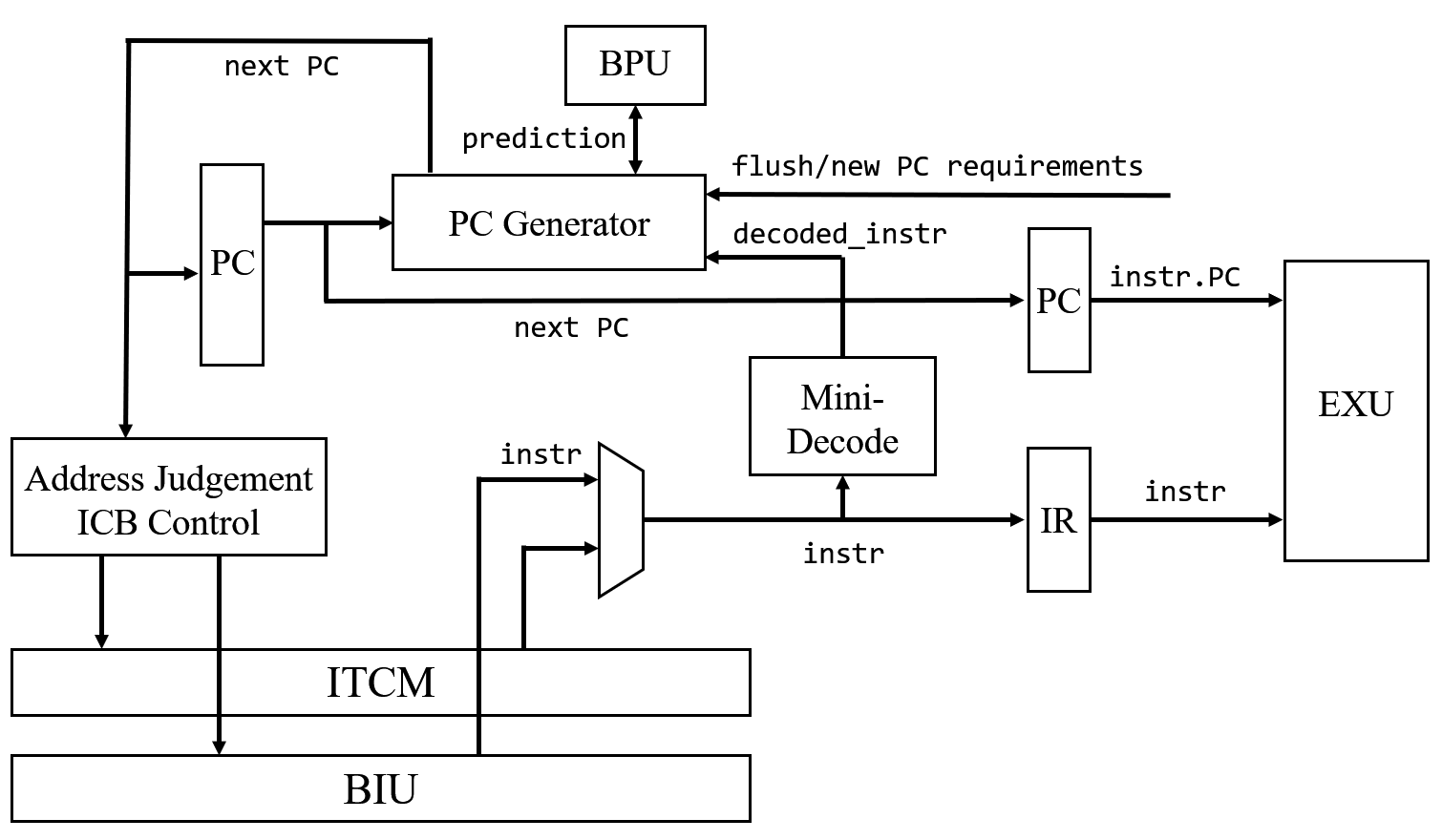
它试图“快速”且“连续”地获取指令。
E203 假设大多数指令存储在 ITCM 中,
因为它专为超低功耗、嵌入式场景设计,
它不会加载长代码。
通常代码都可以加载到 ITCM 中。
IF 模块只需一个周期即可获取一条指令,
这已经达到了快速的要求。
当它需要从 BIU 获取指令时,
会有更多的延迟,但这种情况远少于 ITCM,
因此 E203 没有为这些情况进行优化
(为了更高的性能,可能需要这样的优化)。
对于“连续性”,
每次 IF 都应该预测下一个 PC 值。
IF 部分解码获取的指令并判断是否需要跳转。
如果需要,
分支预测器在同一周期运行,
IF 使用结果和解码信息来生成下一个 PC。
Mini-decode (微型译码)
此模块只需要判断它是通用指令还是分支指令。
为了简化设计过程,
此模块通过实例化一个完整的译码模块来实现,
将不相关的输入接地,输出不连接。
综合工具会优化冗余逻辑,最终实现一个微型译码器。
1 |
|
我们将在后续章节中详细研究译码模块,而不是在这里。
Ready/Valid握手
Ready/Valid 握手是一种协议,用于确保两个设备之间数据的正确传输。
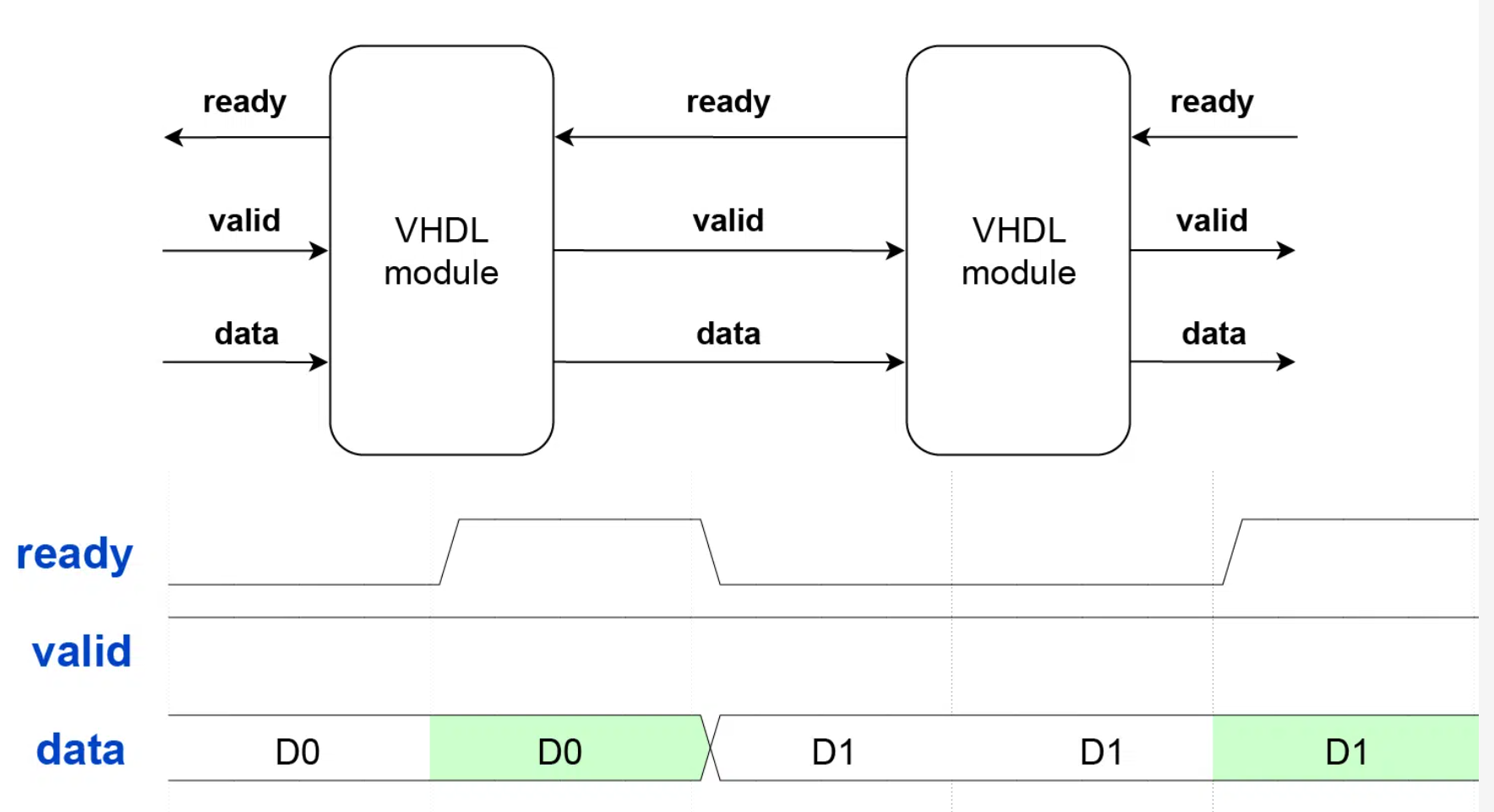
规则很简单:
数据传输仅在同一个时钟周期内,ready 和 valid 都为 ‘1‘ 时发生。
握手是一种无状态协议。
任何一方都不需要记住前一个时钟周期的事件
来确定当前周期是否发生数据传输。
此外,双方必须同步操作,并在同一时钟边沿读取控制信号。
因此,ready/valid 不适用于跨时钟域 (CDC)。
简单的 BPU 分支预测器
为了实现低功耗,E203 应用了最简单的静态预测。
对于条件直接跳转指令,
向后跳转被预测为需要跳转;
否则,预测为不需要跳转。
同时 BPU 通过 PC + offset 生成下一个 PC。
文件位于模块 e203_ifu_litebpu.v
1 |
|
在 RISC-V 结构中,x1 默认用作“返回地址”。
在大多数情况下,jal 和 jalr 会将下一条指令的地址返回到 x1,除非特别指定。
因此,在大多数情况下,地址将存储在 x1 中。
为了提高性能,
E203 为 x1 隐含了特殊的加速。
1 | wire dec_jalr_rs1x1 = (dec_jalr_rs1idx == `E203_RFIDX_WIDTH'd1); |
这行代码用于判断 jalr 是否使用了 x1。
此外,它还需要判断是否存在 RAW 冒险。
当满足以下条件时,存在 RAW 冒险:
- OITF 不为空,意味着一条长指令正在执行。结果可能会写回
x1。
(当然它可以使用其他寄存器,但这里应用了保守估计以减少面积。性能损失被忽略。) - IR 寄存器中的指令会将结果写回
x1。
所以
1 | wire jalr_rs1x1_dep = dec_i_valid & dec_jalr & dec_jalr_rs1x1 & ((~oitf_empty) | (jalr_rs1idx_cam_irrdidx)); |
用于指示依赖性。下一行
1 | assign bpu_wait = jalr_rs1x1_dep | jalr_rs1xn_dep | rs1xn_rdrf_set; |
如果检测到依赖性,则将 bpu_wait 拉高一个周期。
这样的信号将停止 IFU 的下一个 PC 生成,直到 RAW 冒险消失。
通常,这种延迟(停顿)会导致一个周期的性能损失。
如果 jalr 使用了 x0 和 x1 以外的寄存器,
E203 没有应用特殊加速。
要读取 xn,需要寄存器堆的第一个读端口。
只有当端口为空时,才能读取 xn。
同时,IR 必须为空以防止 RAW 冒险
(同样,忽略性能损失)。
如果 RAW 冒险和读端口都空闲,
则拉高端口的使能并占用它。
1 | wire rs1xn_rdrf_set = (~rs1xn_rdrf_r) & dec_i_valid & dec_jalr & dec_jalr_rs1xn & ((~jalr_rs1xn_dep) | jalr_rs1xn_dep_ir_clr); |
访问内存
为了提高代码密度,
E203 支持 16 位压缩 RISC-V 指令集。
因此,32 位指令与 16 位指令混合,
导致了 32 位指令的非对齐。
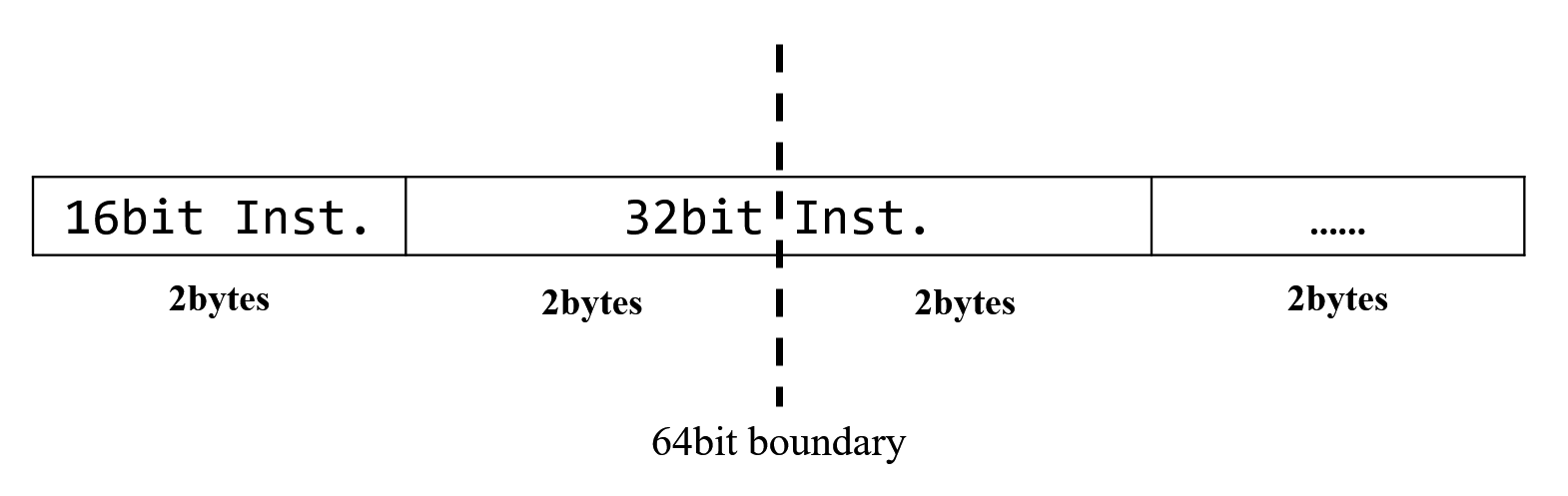
为了处理这个问题,
E203 应用了剩余缓冲区 (leftover buffer)。
IFU 每次从 ITCM 或 BIU 获取 32 位数据。
如果 IFU 访问 ITCM,
由于 ITCM 由 SRAM 组成,
读取后,端口的值将保持不变(不变)直到下次读取。
这种特性节省了一个 64 位寄存器。
E203 中 ITCM 的位宽是 64 位。
一次读取操作从端口读取 64 位数据,称为一个 Lane。
当通过地址递增来获取指令时,
IFU 由于 E203 中的 RISC-V 指令最长为 32 位,因此会多次从同一个 Lane 获取数据。
这减少了读取 SRAM 的次数,因为 IFU 可以从保持值的端口读取数据,直到所有数据都被读取。
如果一条 32 位指令跨越了 64 位边界,
新的 64 位数据中的剩余 16 位将被存储在剩余缓冲区中,
并触发一次新的 SRAM 访问。
来自 SRAM 的新 64 位数据中的最低 16 位与剩余缓冲区中的 16 位
将被连接成一条完整的 32 位指令。
这相当于在一个周期内获取一条 32 位指令,
没有任何性能损失。
如果遇到跳转指令或流水线刷新,
并且所需的指令跨越了 64 位边界,
那么需要两次连续的 SRAM 读取。
这意味着获取指令必须花费两个周期,
引入一个周期的损失。
E203 选择放弃优化,因为它会带来过多的额外面积和功耗成本。
参考资料:
[1] 胡振波, RISC-V架构与嵌入式开发快速入门, 第1版. 北京: 人民邮电出版社, 2019.
[2] 胡振波, 手把手教你设计CPU——RISC-V处理器, 第1版. 北京: 人民邮电出版社, 2018.